Statistical image reconstruction strategies
Let us add to our earlier equation the assumption that the linear system of equations are only valid as an expected 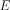 value of some statistical quantities:
value of some statistical quantities:
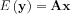
thus the incoming information, the measured data is not "carved into stone", exact values but -even when no noise is present- it can take "legally" multiple values while the x unknowns do not change. The linearity of the operator projecting the unknowns to the space of the measure data can be also interpreted as statistical independence, e.g. in emission tomography the radioactive decays happening in one voxel are independent of the decays happening in the adjacent voxel, while for transmission tomography linearity only holds if we disregard spectral changes.
Let us generalize our model where the acquired data and the unknowns are connected by a probability density function (pdf) describing the probability of obtaining y data given the unknowns take a value x; let us choose the notation for this pdf as 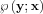 . When also x is regarded as a random variable, we should include that in the notation:
. When also x is regarded as a random variable, we should include that in the notation: 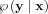
Maximum-Likelihood estimation
A basic statistical estimation theory tool is the Maximum-Likelihood estimation, when we look for the x parameters where a given measured data would occur with the maximum likelihood, i.e. our estimation could be formalized as
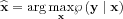
The majority of the measurable physical quantities can be modeled using the exponential distribution family therefore the maximization criteria is set to the logarithm of the likelihood function .
The Maximum Likelihood estimation is in theory and practice both a very basic mathematical tool that we are not going to dwell on but only show an example for those wishing to brush up their memories.
Example for teh Maximum Likelihood estimator can be found on a separate page.
Bayes estimation and the Maximum Aposteriori criteria
Now let us look at the x model parameters as random variables, and look at the probability that if we acquired y measured data what would the pdf of the parameters be:
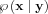
The Bayes-estimation maximizes this probability, that is, how the reply is given to the question of what would be the most probable parameter set given the measured data?. This probability can be considered as aposteriori, i.e. post-measurement pdf, hence is the name Maximum Aposteriori (MAP) technique.
In mathematical symbols using the Bayes-theorem:
![$ \mathbf{\widehat{x}}=\arg \underset{\mathbf{x}}{\max} \wp \left ( \mathbf{x}\mid \mathbf{y} \right )=\arg \underset{\mathbf{x}}{\max} \frac{\wp \left ( \mathbf{y}\mid \mathbf{x} \right )}{\wp \left ( \mathbf{y} \right )}\wp \left ( \mathbf{x} \right )=\arg \underset{\mathbf{x}}{\max}\left [ \ln \wp \left ( \mathbf{y}\mid \mathbf{x} \right )+\ln \wp \left ( \mathbf{x} \right ) \right ]](lib/equation/pictures/5c7dd0a59b72d7cefd0179ceee5dfe82.png)
The first maximization term is already known to us from the Maximum-Likelihood estimation, the second depends on the pdf of the parameters this one contains our apriori knowledge, and is called the prior. Its interpretation is that the parameters cannot take any arbitrary value since the activity concentration value for example can never exceed the activity concentration of the radiopharmacon administered.
Our pre-examination knowledge may be very hard to mathematically formulate. In practice the priors are very simple conditions like the continuity or smoothness of the spatial distribution of x. As the ln functionis often applied the priors are also given often in an exponential form, called Gibbs-priors:
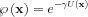
For example if our apriori knowledge is that if a voxel has a certain reconstructed value than its neighbors should not be much different, the U(x) potential a can be proportional with the distance of the voxel from the voxel in question.
Maximum-Likelihood Expectation Maximisation (ML-EM ) algorithm
An extension of the Maximum Likelihood method is the iterative Maximum-Likelihood Expectation Maximisation method with involving virtual random variables in the modelling that increases modeling accuracy while simplifies the maximisation procedure. The ML-EM method can also involve priors, then it is called the MAP-EM method.
As the ML-EM method is a fundamental tool in medical imaging we will go into details in the next section.
The original document is available at http://537999.nhjqzg.asia/tiki-index.php?page=Statistical+image+reconstruction+strategies